Policy function calculation from value function iterations
We approximate the following random model without labor:
![]()
for
![]()
and
![]()
where ![]() and
and ![]() are error terms
with mean zero.
are error terms
with mean zero.
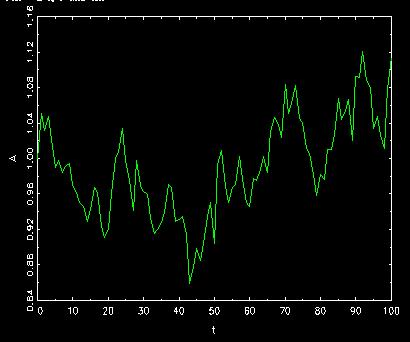
A path of A
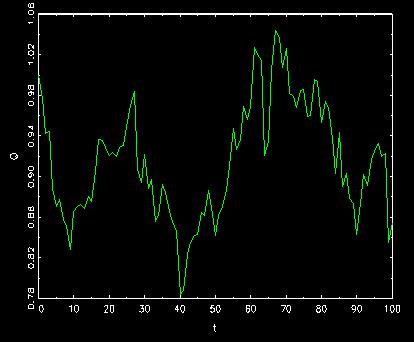
A path of Q
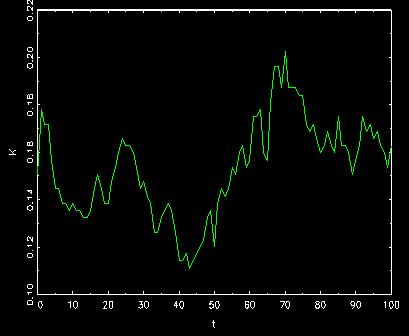
The corresponding behavior of K
We approximate the following random model without labor:
![]()
for
![]()
and
![]()
where ![]() and
and ![]() are error terms
with mean zero.
are error terms
with mean zero.
A path of A
A path of Q
The corresponding behavior of K