Speedup algorithm: error bounds
Recall the following m states model:
![]()
![]()
![]()
.
.
.
![]()
where
![]()
![]()
![]()
.
.
.
![]()
with probability matrix:
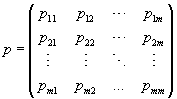
whose row sums are all zeros as in 0812.
We firstly compute m policy functions corresponding to each theta and then pick a
policy function according to the probability matrix.
We implement the same algorithm of error bounds as yesterday’s when we compute
m policy functions respectively.