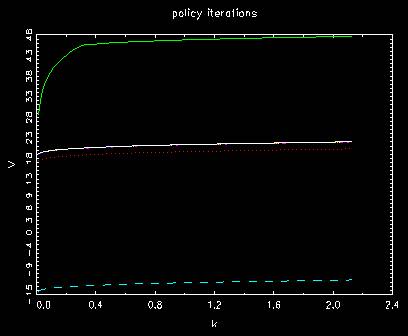
Speedup algorithm: policy iterations
We repeat the process to update value function up until policy function of capital
converges and stops shifting. We do this by seeing the changes of value functions
in terms of utility. Given k and k’, we calculate u as r and solve
V=r+beta*V
for V and get V=(1/(1-beta))*r. That is the exact amount of change in value function
form the current policy function to the next.
The convergence of policy function is attained before that of value function in
a regular meaning. We here modify the definition of value function in terms of utility
and see the convergence.
Behavior of regular value function
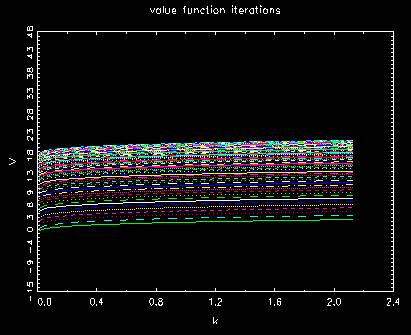
Behavior of value function in policy iterations
The number of unmatched indices in each case
t= 1 diff #= 99
t= 2 diff #= 100
t= 3 diff #= 100
t= 4 diff #= 87
t= 5 diff #= 20
t= 6 diff #= 2
t= 7 diff #= 1
t= 8 diff #= 0
.
.
.
t= 359 diff #= 0
t= 360 diff #= 0
t= 361 diff #= 0
t= 361
t= 1 diff #= 99
t= 2 diff #= 100
t= 3 diff #= 100
t= 4 diff #= 87
t= 5 diff #= 20
t= 6 diff #= 2
t= 7 diff #= 1
t= 7
where we see zeros for the first one after t=7. It means that policy function matches
long before value function converges.