Speedup algorithm: policy iterations
With leisure utility, we only change functional settings:
fc(k,k1)=A*k^alpha*lstar^(1-alpha)+(1-delta)*k-k1
and
fu(x)=(x^(1-th)-1)/(1-th)+h(lbar-lstar)
for the same procedure. Here, we compute constant labor lstar from FOC of Bellman
equation with respect to labor. Given lstar, we set these above to the same procedure.
Behavior of regular value function
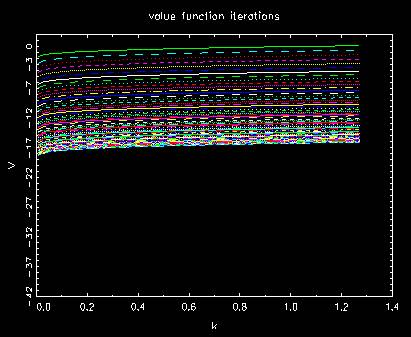
Behavior of value function in policy iterations
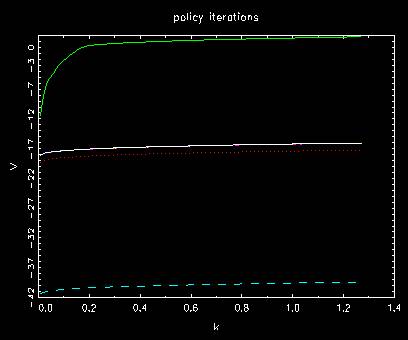
where first one converges from the top as done before.
The number of unmatched indices in each case
t= 1 diff #= 99
t= 2 diff #= 100
t= 3 diff #= 100
t= 4 diff #= 87
t= 5 diff #= 20
t= 6 diff #= 2
t= 7 diff #= 1
t= 8 diff #= 0
t= 9 diff #= 0
.
.
.
t= 358
t= 1 diff #= 99
t= 2 diff #= 100
t= 3 diff #= 100
t= 4 diff #= 87
t= 5 diff #= 20
t= 6 diff #= 2
t= 7 diff #= 1
t=
7