Speedup algorithm: policy iterations
We approximate the continuous random model without labor:
![]()
by switching model with infinite many states in order:
![]()
![]()
![]()
.
.
.
where
![]()
![]()
![]()
.
.
.
for many states.
We calculate each policy function for each![]() as it is set like:
as it is set like:
![]()
independently for each i and calculate the next index number.
The random process![]() can be
can be
![]()
for ![]() as before.
as before.
When we compute each policy function for
each![]() , we apply policy iterations.
, we apply policy iterations.
Random behavior of ![]()
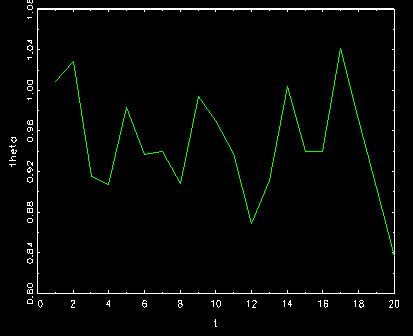
The corresponding behavior of capital
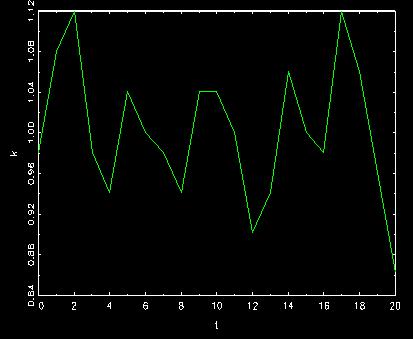
where we can find that these two movements are a little bit different
when we magnify the pictures.