Speedup algorithm: Both error bounds and policy iterations
We perform value function iterations with error bounds and then apply policy
iterations based on the results of the modified value function iterations.
Behavior of value function in policy iterations
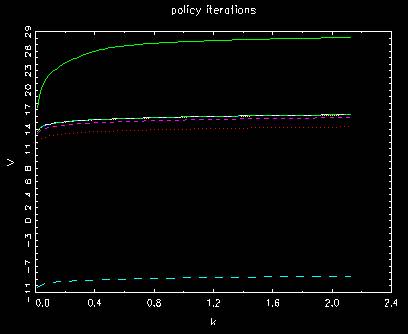
Behavior of value function in policy iterations with error bounds
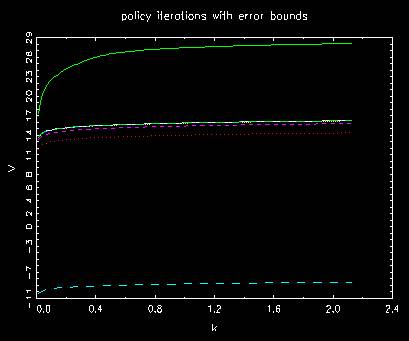
where the two above are almost the same. There is no improvement at all.
The number of unmatched indices in each case
t= 1 diff #= 99
t= 2 diff #= 100
t= 3 diff #= 100
t= 4 diff #= 99
t= 5 diff #= 86
t= 6 diff #= 29
t= 7 diff #= 12
t= 8 diff #= 1
t= 9 diff #= 3
t= 9
t= 1 diff #= 99
t= 2 diff #= 100
t= 3 diff #= 100
t= 4 diff #= 99
t= 5 diff #= 86
t= 6 diff #= 29
t= 7 diff #= 12
t= 8 diff #= 1
t= 9 diff #= 3
t= 9
where those without and with error bounds usually lead to exactly the same results
as long as the number of iterations are the same.
The method of error bounds is a kind of redundant to the method of policy iterations.
This method is highly optional. We only have to select either error bounds or policy
Iterations.