Speedup algorithm: Modified policy iterations
The algorithm of modified policy iterations is
(1) Set a grid consisting of k and k' columnwise and rowwise respectively.
(2) Calculate utility for consumption as U using the grid matrix above.
(3) Starting from a certain v, update v1=U+beta*v' so as to maximize v1.
(a) Find the corresponding k’ from (3) in value function iterations.
(b) Calculate utility from k and k’ as r.
(c) Starting from a certain vp, update vp1=U+beta*vp where vp is calculate by
vi=r+beta*vi_1
up until vi and vi_1 are almost the same
and set the final vi to vp.
(d) Repeat the whole thing by setting vp=vp1 until some criterion is met.
(4) Repeat (3) by setting v=v1 for many times.
(5) Find the final corresponding value of k as k' according to the maximum value.
The main difference is by direct inversion or by numerical iterations.
Theoretically, they are the same. However, the modified version takes more iterations
due to errors in convergence criteria.
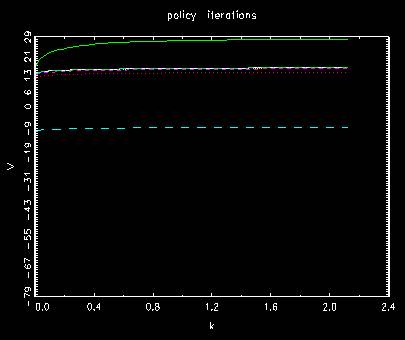
Behavior of value functions for original policy iterations
Behavior of value functions for modified policy iterations
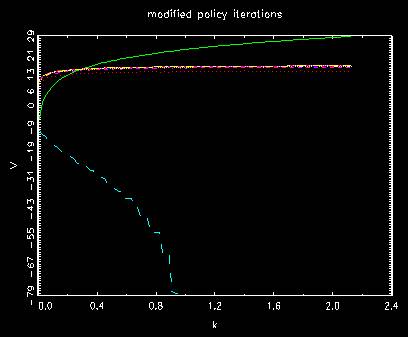
where the first two are different from the former method and the rest
is involved to a little bit more iterations to final position. In both, they shift from up to
bottom once and then going up to the final position gradually.
The number of unmatched indices in each case
t= 1 diff #= 99
t= 2 diff #= 100
t= 3 diff #= 100
t= 4 diff #= 99
t= 5 diff #= 86
t= 6 diff #= 29
t= 7 diff #= 12
t= 8 diff #= 1
t= 9 diff #= 3
t= 9
t= 1 diff #= 99
t= 2 diff #= 100
t= 3 diff #= 100
t= 4 diff #= 99
t= 5 diff #= 86
t= 6 diff #= 29
t= 7 diff #= 12
t= 8 diff #= 1
t= 9 diff #= 3
t= 10 diff #= 2
t= 11 diff #= 0
t= 12 diff #= 0
t= 12
where the first case by policy iterations stops earlier than t=10 while the second case
by modified policy iterations stops later.