Speedup algorithm: Modified policy iterations
With leisure utility, we only change functional settings:
fc(k,k1)=A*k^alpha*lstar^(1-alpha)+(1-delta)*k-k1
and
fu(x)=(x^(1-th)-1)/(1-th)+h(lbar-lstar)
for the same procedure.
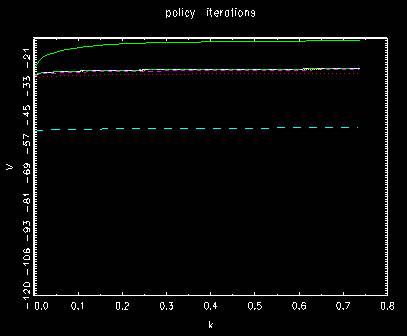
Behavior of value functions for policy iterations
Behavior of value functions for modified policy iterations
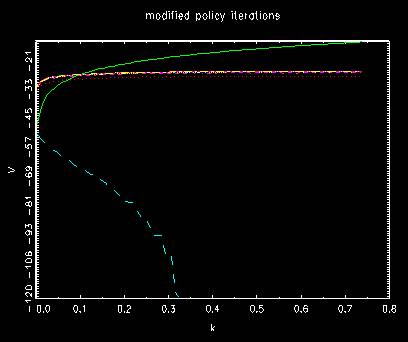
where the first two are different from the former method and the rest
is involved to a little bit more iterations to final position. In both, they shift from up to
bottom once and then going up to the final position gradually.
The number of unmatched indices in each case
l*= 0.34678000
k*= 0.37462647
t= 1 diff #= 99
t= 2 diff #= 100
t= 3 diff #= 100
t= 4 diff #= 99
t= 5 diff #= 86
t= 6 diff #= 29
t= 7 diff #= 12
t= 8 diff #= 1
t= 9 diff #= 3
t= 9
t= 1 diff #= 99
t= 2 diff #= 100
t= 3 diff #= 100
t= 4 diff #= 99
t= 5 diff #= 86
t= 6 diff #= 29
t= 7 diff #= 12
t= 8 diff #= 1
t= 9 diff #= 3
t= 10 diff #= 2
t= 11 diff #= 0
t= 12 diff #= 0
t= 12
where the first case by policy iterations stops earlier than t=10 while the second case
by modified policy iterations stops later.