Behavior of capital
We use k0’=SmoothingFunction(k’,k,k0) in general given k’ and k and we find the next by
ks[t]= SmoothingFunction(k’,k,ks[t-1]) from t=2 to np
starting from some point ks[1].
Capital approaches to the steady state level depending on how good to estimate.
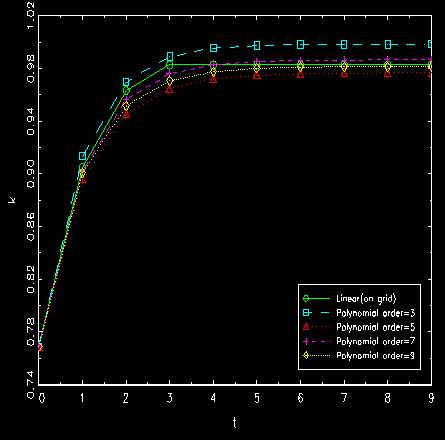
As the number of order for polynomial gets larger, the resulting trajectory is going to be
close to the actual movement based on the true policy function.
Some bad approximation may lead to no convergence for a long time.
The trajectory by linear interpolation from a point on the gird is the same as what
we got on the gird before.