Collocation method with transition matrix
Value function approximation we implement is a kind of policy function iterations.
After getting to some convergence of value function, we get the corresponding
policy functions in terms of index numbers.
Today we use the index numbers to see the movement of capital by switching policy
functions according to transition matrix. We do not set policy function interpolation
for now.
The movement of capital
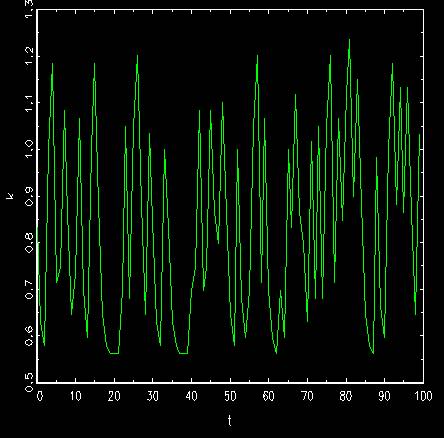
where the movement is based on the policy functions with some random pick of them
according to transition matrix. We just change the convergence criterion of value
function to collocation method. The behavior will not be changed at all.