Beyond curse of dimensionality
Today we use non-aggregate model and add technology change and make it fluctuate
according to some random process. We approximate the continuous random model:
![]()
by switching model with infinite many states in order:
![]()
![]()
![]()
.
.
.
where
![]()
![]()
![]()
.
.
.
for many states.
We calculate each policy function for each![]() as it is set like:
as it is set like:
![]()
independently for each i and calculate the next index number.
The random process![]() can be
can be
![]()
for ![]() as in 0818.
as in 0818.
We implement column-by-column calculation:
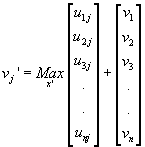 from j=1 to
n
from j=1 to
n
when we calculate each index vector. We then smooth out the points on the gird by one
of the following:
0:linear interpolation
1:polynomial
2:LOESS
3:LOWESS
4:Kernel regression
5:Smoothing natural spline
6:NURBS
7:Bezier Curve
locally by index numbers around the evaluated points only.
We set k[ind[indn]] and k[indn] rather than k1=k[ind] and k.
We can save memory and increase n beyond curse of dimensionality.